You type something into Google. Half a second later, you have answers.
It feels effortless - almost magical. But behind that half-second is one of the most sophisticated engineering systems ever built, silently doing billions of operations before your finger lifts off the enter key.
Most people never think about what actually happened. They got their answer, they moved on.
But the result that showed up first wasn't random. It wasn't the "best" page on the internet for your query in any objective sense. It was the page that won a very specific, very mechanical competition - one governed by rules most people don't know exist. And the pages that didn't make it to the first page weren't necessarily worse. They just lost that competition in ways their creators didn't understand.
Understanding how that machine works doesn't just make you better at SEO. It changes how you think about publishing anything on the web.
The Machinery
Before you can think clearly about strategy, you need to understand the machine. Not at a surface level - mechanically. Because the moment you see how each stage works, a lot of conventional SEO advice starts to either make obvious sense or fall apart completely.
There are four stages every web page passes through before it can ever appear in your results. Let's go through all of them.
Web Crawling & Discovery
The internet has somewhere near a billion websites. Google hasn't been handed a list of all of them. Instead, it sends out automated programs - called crawlers, spiders, or bots to explore the web and bring back what they find.
The process starts with seeds: a set of known, trusted URLs. From those pages, the crawler follows every hyperlink it encounters. Those links lead to new pages, which contain more links, which lead to more pages. Over time, the crawler traces a web of connections that covers an enormous portion of the internet.
This is why internal linking matters in ways people rarely consider. If a page on your site has no links pointing to it - from anywhere on the web, or even from within your own site - a crawler may never find it. It's not that the page is bad. It simply doesn't exist yet from the search engine's perspective.
A page with no links pointing at it is like a room with no doors.
You can build something remarkable inside it. But, Nobody will ever see it.
But crawlers don't have infinite time or resources. Googlebot has what's known as a crawl budget: the number of URLs it will visit on your site within a given time window. That budget is finite, and Google allocates it based on signals like the site's overall authority, how frequently its content changes, and how fast the server responds.
This creates an invisible hierarchy inside every website. High-authority pages on fast, well-structured sites get their new content discovered quickly. Pages buried deep in a site's structure - or sitting on slow servers - may wait days. And if a site wastes crawl budget on low-value URLs (duplicate content, auto-generated parameter pages creating thousands of near-identical variants), the pages that actually matter may not get crawled at all.
Site owners communicate with crawlers using two main tools: robots.txt and sitemaps. Robots.txt is a file placed at the root of a domain that tells crawlers which sections they're allowed or not allowed to access. Think of it as a "do not enter" sign - a well-behaved crawler will respect it, though there's no technical enforcement.
Sitemaps do the opposite: they proactively list the URLs you want the crawler to find, helping it discover pages that might take a long time to reach through link-following alone. If robots.txt is a "do not enter" sign, a sitemap is the map you hand a visitor when they arrive.
The crawl is where everything starts. A page that never gets crawled never gets indexed. A page that never gets indexed cannot rank for anything - regardless of how good the content is.
Indexing & Storage

After the crawler fetches a page, the raw HTML is sent back to Google's servers to be processed. This is indexing - the transformation of a web page into something a search engine can actually search.
The first step is parsing: extracting text, links, images, and metadata from the HTML. The engine notes the title, headings, body text, alt tags on images, anchor text on links, and dozens of other signals - all separated from the surrounding code structure.
Once processed, the content gets stored in what's called an inverted index - the fundamental data structure behind every search engine.
If you've ever flipped to the index at the back of a textbook, you already understand the concept. A book index maps terms to page numbers. An inverted index maps words to documents - and for each document, it stores where the word appeared (title, heading, body), how many times, and alongside which other words.
When you type a query, the search engine doesn't scan every page on the internet. It looks up your keywords in the inverted index and retrieves a pre-built list of matching documents in milliseconds. The index is what makes real-time search possible at the scale of the entire web.
The engineering involved in maintaining this index is staggering. Google's index has been estimated to contain hundreds of billions of pages, taking up petabytes of storage - continuously updated as new pages are crawled and old ones change. Keeping that structure consistent, fast, and current at that scale is one of the less-celebrated achievements in computer science.
The Ranking Algorithm
Here's where it gets interesting. After crawling and indexing, a search engine knows that thousands - sometimes millions - of pages contain the words in your query. Now it has to decide which one to show you first.
This is the ranking problem. And the way search engines solve it tells you almost everything you need to know about SEO.
The algorithm that made Google dominant is called PageRank, named after its inventor Larry Page. The idea is elegant: a link from one page to another is a vote. If a page receives many links, it's likely valuable. But not all votes are equal - a link from a highly trusted, widely-linked page counts more than a link from an obscure one. And the authority cascades outward: a page that receives links from authoritative sources becomes somewhat authoritative itself, making its outgoing links worth more too.
Think of it like academic citation. A research paper cited by the most respected journals in a field carries more weight than one cited only by obscure blogs. The network of citations isn't just about quantity - it's about where the endorsements come from.
PageRank changed how people thought about the web. Before it, search engines mostly matched keywords. After it, the link graph itself became a signal of trust. A page could have exactly the right words, but if nobody linked to it, it wasn't trusted.
But PageRank alone doesn't determine what's relevant to any specific query. That's where TF-IDF comes in.
TF-IDF stands for Term Frequency - Inverse Document Frequency. It's a way of measuring how significant a word is to a specific document, relative to the entire collection of documents.
The Term Frequency part is intuitive: if a word appears many times in a document, it's probably central to what that document is about. But frequency alone is misleading - common words like "the" appear everywhere and tell you nothing distinctive.
The Inverse Document Frequency corrects for this. A word that appears in nearly every document on the web signals almost nothing. A word that appears rarely across the web but frequently within a specific document is a strong signal - it means this page is specifically about something most pages don't cover. Put these together, and the words that matter most are the ones that are common within a document but rare everywhere else. These are the words that distinguish one page from all others.
This is why writing with specific, precise language tends to outperform vague and generic language - not because of keyword tricks, but because specificity is literally how relevance gets signalled in the index.
Modern search has layered many more signals on top of PageRank and TF-IDF. Freshness rewards recently updated content for queries where recency matters - news, trending topics, current events. E-E-A-T - Experience, Expertise, Authoritativeness, and Trustworthiness - is a framework Google uses to evaluate content quality, especially in high-stakes domains like health and finance. Core Web Vitals measure how a page actually performs for real users: load speed, visual stability, how quickly the page responds to interaction.
Neural models now let Google understand meaning rather than just matching words. A query for "how to fix a leaky tap" and "dripping faucet repair" surfaces the same results, because Google's models understand they mean the same thing - even if the pages being ranked never contain your exact phrasing.
The ranking algorithm isn't a single formula you can memorise. It's hundreds of signals combined, weighted differently depending on the type of query, continuously adjusted based on how real users respond to results. The page at position one didn't get there because it checked a list of boxes. It got there because, across all those signals simultaneously, it was the most credible answer.
Query Processing
There's a final stage most people never consider: the gap between what you typed and what the search engine actually understood.
When you enter a query, the search engine doesn't just look for those exact words. It interprets them. It infers intent. It fills in context you never explicitly provided.
The first thing it does is parse your query - breaking it into components, identifying named entities (is "Apple" the company or the fruit?), resolving ambiguity, and expanding with synonyms and related concepts. A search for "best running shoes" triggers consideration of terms like trail shoes, marathon shoes, shoe reviews, and comparisons - because Google's models have learned that people searching that phrase typically want comparison content, not a definition of what running shoes are.
Then comes personalisation. Your location changes results. Your search history changes results. Your device changes results. Two people typing the identical query from different cities, on different devices, with different browsing histories may see meaningfully different rankings. This is why testing your own rankings from your own browser is an unreliable signal - you're not seeing a neutral result, you're seeing one calibrated to you.
Query processing is also where search intent lives. Google categorises queries into rough types: informational (wanting to learn something), navigational (wanting to reach a specific site), commercial (comparing options before a decision), and transactional (ready to act now). The type of content that ranks varies significantly by intent. Informational queries surface long, detailed explanations. Commercial queries surface comparison and review content. Transactional queries surface product pages.
Writing excellent content in the wrong format for a query's intent is one of the most common ways genuinely good work fails to rank. You can write the most comprehensive guide in existence - but if Google has decided that query is transactional, a guide won't rank no matter how good it is.
Understanding query processing is understanding that search isn't really about pages. It's about the match between a page and a person, in a specific context, at a specific moment. The best result for someone in Mumbai searching from a mobile on a Tuesday evening is not necessarily the same as the best result for someone in London on a desktop the following week.
Now you understand the machine. Four stages: crawling to discover, indexing to store, ranking to evaluate, query processing to match. Each has its own logic, its own failure modes, its own levers. Here's what changes when you actually internalize this.
Applying This Knowledge
Most people approach SEO as a layer you add after the content is written. A checklist. A set of boxes to tick. That's exactly why so much well-intentioned content never gets found.
When you understand the machine, SEO stops being a layer and starts being a way of thinking. The four sections below aren't tactics - they're the four stages of the machine, translated into decisions you actually make.
Crawlability
Understanding crawl budget gives you a different way of thinking about site architecture. Every URL on your site is a decision about where to spend the crawler's limited attention. Low-value pages - thin content, duplicate sort/filter variants, auto-generated parameter URLs - don't just fail to rank. They actively consume budget that could have been spent discovering your best work.
Well-structured internal linking isn't primarily a navigation decision. It's a signal to the crawler about what matters. Your most important pages should be reachable from your homepage in as few clicks as possible. Orphan pages - ones that exist but have no internal links pointing to them - are effectively invisible. Even a sitemap submission doesn't fully compensate: a page with no internal authority pointing toward it tells the crawler it's probably not important enough to revisit frequently.
Robots.txt and canonical tags handle the other side of this. Use robots.txt to prevent the crawler from spending time on things that don't need to exist in the index: admin pages, session ID variants, staging environments, duplicate sort orders. Canonical tags tell Google which version of a URL is the definitive one when multiple URLs serve identical or near-identical content.
The mental shift here: your site isn't a collection of pages. It's a graph. The crawler navigates that graph based on its structure. Design the graph intentionally, the same way you'd design anything else.
Content Strategy

TF-IDF tells you something counterintuitive about how to write. Good content isn't about using keywords more. It's about covering a topic with enough depth that the distinctive vocabulary naturally appears.
A shallow article about machine learning that only uses common vocabulary looks, to the index, like a generic piece about anything. A detailed article that gets into gradient descent, loss functions, overfitting, and regularisation - without being instructed to include those terms - signals through its own language that it's genuinely about machine learning. The language of real expertise is the language that signals relevance. You can't fake it by sprinkling in terms you found on a keyword tool. The index notices the difference.
Write specifically enough that a reader who actually knows the topic would say: yes, this person understands this.
Query intent is where strategy meets content format. Before writing anything, search the query yourself and look at what's ranking. Long guides or short answers? Product pages or opinion pieces? Comparison tables or personal narratives? The format of what's ranking tells you what intent Google has assigned to that query. You can produce the best guide that has ever existed - but if Google has decided that query is transactional, a guide won't rank.
Freshness matters differently for different content. Evergreen content - foundational explanations, technical guides, reference material - doesn't need constant rewriting. But revisiting it over time, adding new sections, updating examples, and keeping it accurate signals to Google that the page is actively maintained. News and trending content, by contrast, can rank immediately when fresh but loses position quickly as newer coverage appears. Know which type you're writing and plan accordingly.
Authority

PageRank is still real, even if Google rarely talks about it directly anymore. The quality and relevance of sites linking to you matters - and it matters far more than how many there are.
One link from a highly respected publication in your field does more than fifty links from obscure directories. The reason traces back to the mechanics: authority flows through the graph. A link from a high-trust source passes meaningful weight. A link from a low-trust source contributes almost nothing - and a link from a penalised source can actively work against you.
What actually earns links? The same thing it always has: being the kind of resource that people in a field naturally want to cite. Original research, data others want to reference, the most thorough explanation of a topic that currently exists, something that fills a genuine gap. These earn links without any outreach because other writers encounter them, can't find anything better, and point their readers there.
The mental model shift: your site's authority isn't really yours. It's a function of where you sit in the link network of your field. Building authority means building your position in that network - which means being known to, and useful to, the people who write about your topics.
Sustainable link earning isn't a campaign. It's the long-term result of consistently publishing things worth citing.
Technical Foundation
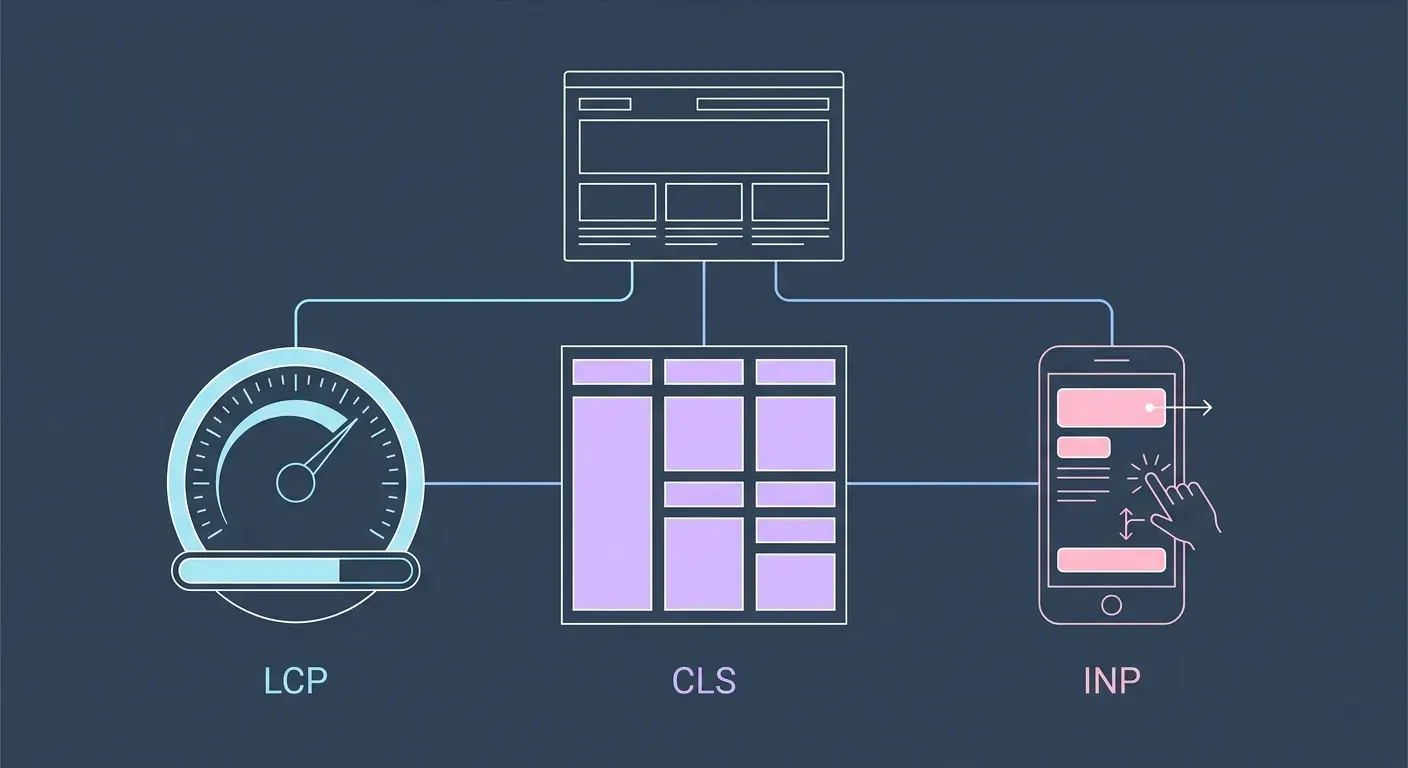
Technical SEO signals are thresholds, not advantages. Getting them right doesn't give you an edge over competitors who also have them right. Getting them wrong creates a ceiling that limits everything else.
Core Web Vitals measure three things: how quickly the largest visible element on a page loads (LCP), how stable the layout is as elements load (CLS), and how quickly the page responds to a user's first interaction (INP). Google uses these as ranking signals - but more practically, they measure whether your page is actually usable. A slow, layout-shifting page loses users before they read a word. No amount of content quality compensates for that.
HTTPS is table stakes at this point. Mobile performance matters because the majority of searches now happen on mobile, and Google's index is mobile-first - meaning your mobile experience is what gets evaluated, not your desktop one. If your site looks great on a wide screen but breaks on a phone, the version that's being ranked is the broken one.
Structured data (schema markup) is the one technical signal that actively adds capability rather than just clearing a disadvantage. By annotating your content with structured data, you give Google machine-readable context about what a page actually is - a recipe, a product, a review, an FAQ, an article. This can unlock rich results: enhanced listings in search with ratings, prices, steps, or answers visible directly on the results page. Rich results don't always improve rankings, but they consistently improve click-through rates by making your listing visually distinct from everything around it.
Think of technical SEO as the floor your content sits on. It needs to be solid, level, and clean. Everything else is what you build on top of it.
Conclusion
Most people approach search engines as systems to outsmart. A set of rules to comply with, or loopholes to work around. The tactics change constantly, and people who build strategies on tactics spend their lives constantly adapting to the last algorithm update.
Understanding the machine changes the frame entirely. When you know a crawler is navigating your site's link graph, architecture becomes an obvious consideration. When you know how an inverted index signals relevance, you stop stuffing keywords and start writing with specificity. When you understand that PageRank is about position in a network of trust, link-building stops being a volume game and starts being about relationships and genuine value.
Search engines are trying to solve a genuinely hard problem: connecting people with the most useful, trustworthy information they can find, faster than any human librarian could. When your content genuinely helps with that problem, the algorithm has every incentive to surface it. When it doesn't - when the content exists primarily to manipulate ranking rather than to answer something - the machine is increasingly good at telling the difference.
The best SEO isn't tricks. It's alignment with how search actually works.
The machine isn't against you. It just doesn't care about your intentions - only your output.