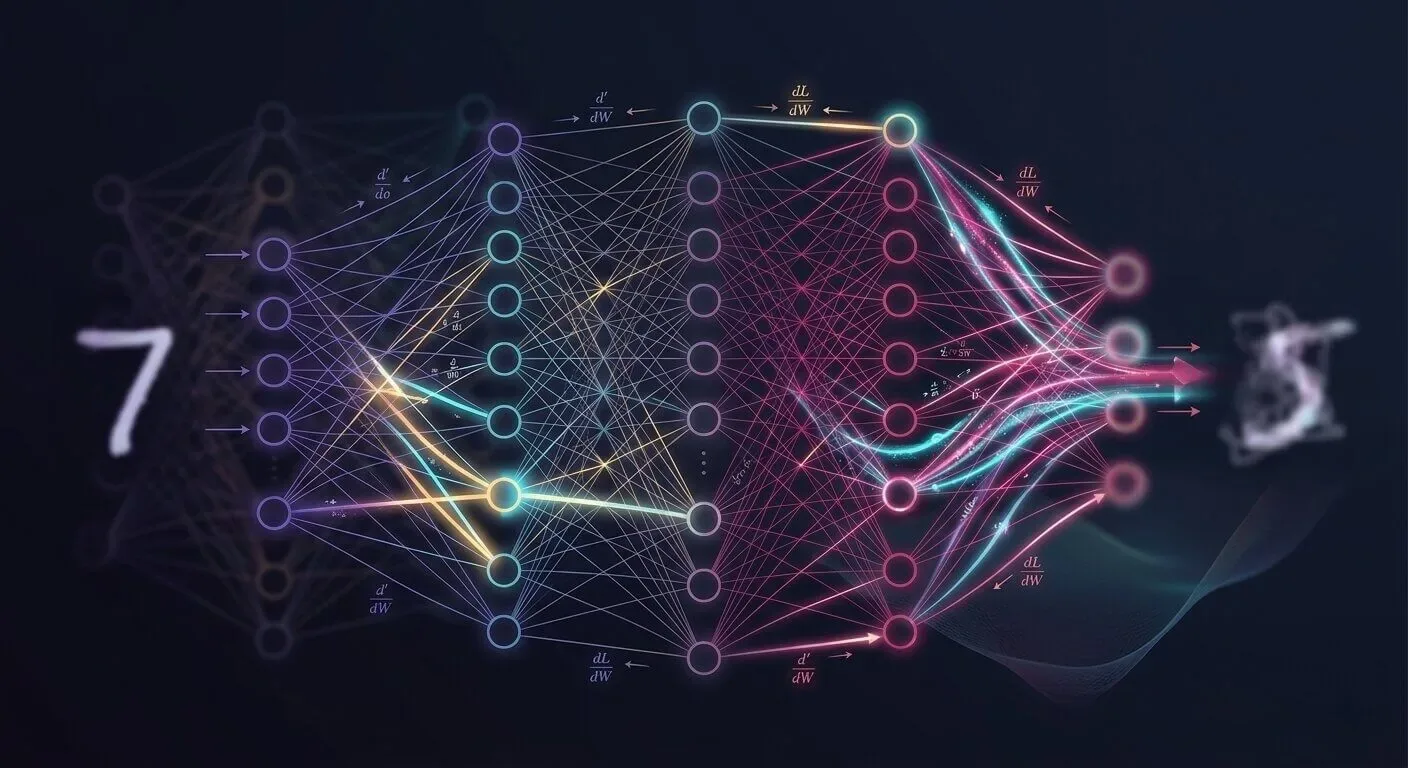
Your brain has never read a textbook on how to recognise faces. Yet you can glance at a stranger across a crowded room and instantly know: that's a person, that's a smile, that's someone you haven't met before. No one programmed that in. You just... learned it.
Artificial neural networks learn the same way. Not through rules written by hand, but through repetition and correction. Show the network enough examples. Tell it when it's wrong. Let it adjust. Repeat.
The mechanism that makes that adjustment possible. The thing that actually does the learning. Is called backpropagation. This guide is about how it works in detail and in a beginner friendly way.
Recap
If you've already read our introduction to neural networks, you know the setup: a network of neurons, each holding a number, connected by weights and biases, processing signals layer-by-layer until an answer comes out the other end.
If that's new to you, don't worry! everything you need to follow along will be explained as we go. But if you'd like the full foundation first, this guide builds it from scratch in a beginner friendly way. How Do Neural Networks Learn?
At the heart of the problem is a simple and slightly uncomfortable truth. When a neural network is first created, every weight and every bias is just a random number. The network has no knowledge. No intuition. No sense of what it's doing. Ask it to identify a handwritten digit and it might look at a clearly drawn 7 and confidently declare it's a 2. It's not being careless. It genuinely has no idea yet.
So, the question becomes: How do you take a network full of random numbers and turn it into something useful?
You do it the same way you'd correct anything: figure out what went wrong, trace it back to its cause, and fix it. Then just do that thousands of times.
That's backpropagation. Not magic. Not intuition. Just a very systematic way of asking: Who's responsible for this mistake? And making sure everyone contributes towards improving that mistake.
The key insight here is that the forward direction of a network is easy. Signal flows in, math happens layer-by-layer, an answer comes out. But learning requires going the other direction. Taking that wrong answer, and working backwards through every layer to figure out how much each weight and bias contributed to the error. And which direction they need to shift to do better next time.
That backwards journey is what gives backpropagation its name. And by the end of this guide, you'll be able to follow every step of it.
Measuring The Mistake
Before we can fix anything, we need to know how wrong the neural network actually is. Not in vague terms, but as a number. Something that we can calculate, compare, and eventually reduce.
This is where the loss function comes in. Think of it like a cost. Lesser the better.
After the network produces an output, the loss function compares it against the correct answer from the training data and returns a single number summarising the gap. A loss of zero means the network was exactly right. A higher loss means it missed. The higher the number, the worse the miss.
Let's understand this better with an example:
Say we're training a network to recognize handwritten digits. We show it a 7. The network outputs a confidence value for each digit from 0 to 9, representing how strongly it believes the input matches that digit. In a perfect world, the output would look like this:
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
But our untrained network is still full of random numbers. It might instead output something like this:
| 0.3 | 0.2 | 0.9 | 1.0 | 0.3 | 0.5 | 0.1 | 0.1 | 0.6 |
These are completely random values only for demonstration of the core concept.
That's clearly wrong. But "clearly wrong" isn't a number we can work with. We need to quantify it.
The most natural instinct is to look at each digit, take the difference between what the network gave us and what we expected, and add them all up. That works. But there's a subtler option that works better in practice: instead of the raw difference, we take the squared difference.
Here's why that matters:
For digit 7, we expected 1.0 but got 0.1. The raw difference is 0.9. Squared, that's 0.81. Still significant.
For digit 5, we expected 0.0 but got 0.3. The raw difference is 0.3. Squared, that's 0.09. Suddenly tiny.
Notice what squaring did there. It didn't just measure the mistake; it emphasised the bigger ones and compressed the smaller ones into near-irrelevance. A network that's catastrophically wrong on one output looks much worse than one that's slightly off everywhere. Which is exactly the behaviour we want. Small residual errors matter far less than big confident mistakes.
We sum these squared differences across all outputs and average them. The result is called the Mean Squared Error.
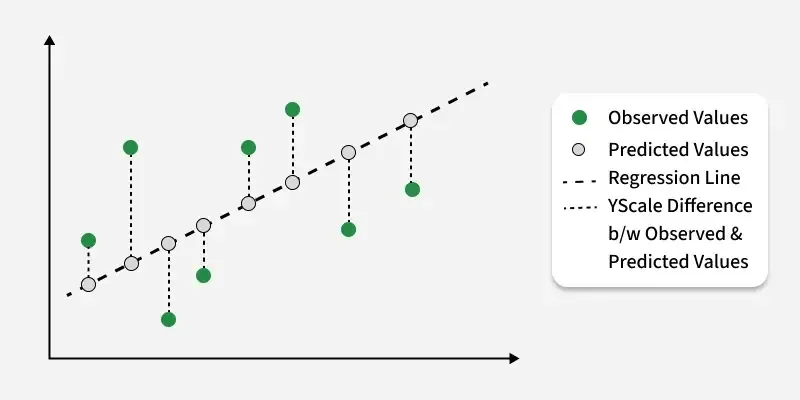
With the help of mean squared error, we have a single number. The loss. And our goal from here is simple: make it smaller. By nudging the weights and biases towards the right direction and by the right amount.
The Right Direction
We have a number that tells us how wrong the network is. And we know we want to make it smaller. But here's the problem. An average usable neural network has thousands, sometimes millions of weights and biases. See each of them as a dial that we could turn. Turning any one of them can change the network's loss. But how do we know which ones to turn, and in which direction?
If you nudge that weight slightly in one direction and the loss goes up, that's the wrong direction. Nudge it the other way and the loss goes down. That's the direction we want. Do this for every weight and bias in the network, and you have a full picture of which way each parameter needs to move to reduce the overall mistake. Then we just do this trial and error method for every weight and bias till the network stops being wrong.
This idea has a name: Gradient descent.
Imagine the network's loss as a landscape of hills and valleys. Every possible combination of weights and biases corresponds to some point in that landscape, and the height at that point represents the loss. Our goal is to find the lowest valley.
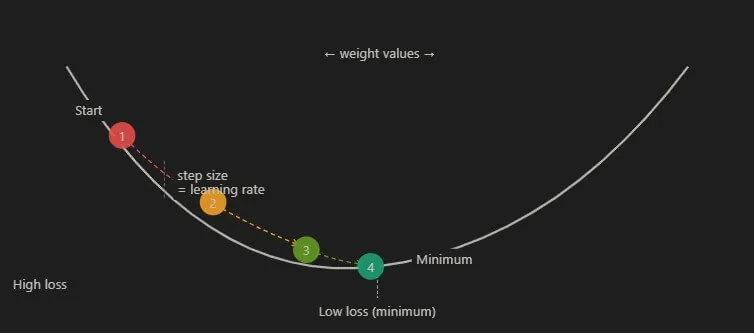
The gradient is just the slope of that landscape at wherever you're currently standing. It tells you the direction of steepest uphill. And since we want to go down, we move in the exact opposite direction. One small step. Then we check the slope again. Then another step.
Each step is one update to the network's weights and biases. How large a step? That's controlled by a value called the learning rate. Too large, and you overshoot the valley and bounce around the walls forever without settling. Too small, and training crawls at an impractical pace.
There's one catch though. Computing the gradient tells us that we need to step downhill. It does not tell us how each individual weight contributed to the slope we're standing on. With millions of weights, we can't just nudge each one manually and see what happens. We need a smarter way to trace the slope back to every parameter simultaneously.
That's exactly what backpropagation helps us in.
A note before we move on: gradient descent is the strategy. Find downhill and step toward it. Backpropagation is the mechanism that makes gradient descent possible at scale. The calculation that figures out, for every single weight in the network, which direction is downhill and by how much.
They're not the same thing, but they work together as a pair. Gradient descent decides where to go. Backpropagation does the legwork of figuring out how to get there.
Tracing the Blame
Let's start with a question that sounds simple but isn't:
The network made a mistake. The loss told us how bad it was. But it's just a single number at the end of the network. The weights responsible for that mistake are scattered across every layer. Some close to the output, some way back near the input. How do we figure out how much each one is to blame?
The answer: working backwards one layer at a time.
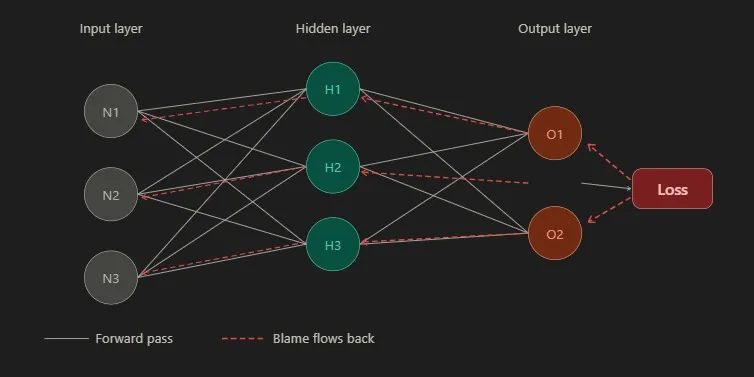
Think about how the loss was produced. The output neurons fired based on signals from the hidden layer. The hidden layer fired based on signals from the input layer. Every neuron in every layer had some influence on the final answer. The question is just: how much?
We start at the end, right next to the loss. The output neurons are the most directly responsible. We can measure exactly how much each output neuron's value contributed to the loss, because the loss function is just a formula and we can take its derivative with respect to each output. That derivative tells us: if this output went up slightly, would the loss go up or down, and by how much?
Now we move one layer back. The hidden layer neurons produced the output that the output neurons acted on. So we ask the same question there: if this hidden neuron's value changed slightly, how would the output change? And how would that then affect the loss?
You can see where this is going. We keep applying the same logic, one layer at a time, all the way back to the first layer. At every step we're asking the same small question: if I changed this value slightly, what would happen downstream? And we multiply the answers as we go.
The Chain Rule
That multiplication is not an accident. It has a name: the chain rule.
If A affects B, and B affects C, then a small change in A affects C through B. The chain rule in calculus gives us a clean way to compute that: the rate at which A affects C equals the rate at which A affects B, multiplied by the rate at which B affects C.
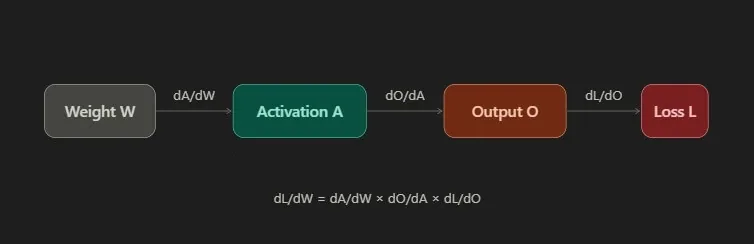
In a neural network, the chain of influence goes: weight → activation → next layer activation → ... → output → loss. Backpropagation walks this chain in reverse. At each step it computes the local derivative, the rate at which this layer's values affect the next one. Then it multiplies all those local derivatives together to get the full gradient: how much does this weight, way back near the input, affect the final loss?
This is why the process is efficient. You don't need to separately test each of the millions of weights. You compute one backward pass through the network, reusing calculations as you go, and every single gradient falls out at the end. What would otherwise take millions of individual experiments now takes roughly the same time as a single forward pass.
Updating the Weights
Once we have the gradient for every weight and bias, we know two things: which direction makes the loss worse (uphill), and therefore which direction makes it better (downhill). We move every weight a small step in the downhill direction.
The update rule is simple:
Updated weight = current weight - learning rate * gradientRead it like this: the new weight is the old weight, minus a small step in the gradient direction. The Greek letter η (eta) is the learning rate, controlling how large each step is. The gradient dL/dW is what backpropagation gave us: how much this weight contributed to the loss, and in which direction.
A positive gradient means the weight was pushing the loss upward. So we subtract it, moving the weight in the opposite direction. A negative gradient means the weight was helping. We subtract a negative, nudging it further along. Either way, the loss should go down slightly after the update.
Then we do the whole thing again. Show the network another example. Run the forward pass. Measure the loss. Run backpropagation. Update every weight and bias. Thousands of times over thousands of examples. Gradually, the weights stop being random. They settle into values that actually work.
Putting It All Together
Let's step back and see the full picture.
A neural network starts with random weights and biases. It can't do anything useful. We show it a training example and let the signal flow forward, layer-by-layer, until an answer comes out the other end. We measure how wrong that answer is using a loss function. Then we do the reverse journey: backpropagation sends the blame backwards through every layer, using the chain rule to compute exactly how much each weight contributed to the mistake. Armed with those gradients, gradient descent nudges every weight one small step toward reducing the loss. Then we do it all again.
What makes this remarkable is not any single piece. The forward pass is just arithmetic. The loss function is just subtraction and squaring. The chain rule is taught in high school calculus. The weight update is a single line of algebra. But string them all together, repeat them millions of times, and something extraordinary happens: the numbers stop being random and start being meaningful. A network that once couldn't tell a 7 from a 2 starts recognising handwriting with superhuman accuracy. Not because anyone told it the rules. Because the math found its own way there.
Backpropagation is not intelligence. It is not understanding. It is, at its core, just a very efficient way of asking: whose fault was this? And making sure everyone takes a small step toward doing better. The intelligence emerges from doing that, over and over, at scale.
The next time you ask an AI to recognise a face, translate a sentence, or write a paragraph, somewhere underneath it all, this same loop ran. Millions of forward passes. Millions of backward passes. Millions of tiny weight updates. Until the numbers clicked into place.