Your brain has roughly 61 to 99 billion neurons National Library of Medicine. Each one firing signals thousands of times a second. A neural network borrows that exact same idea; and runs it on pure arithmetic. In this guide, we’ll break down how neural networks work, how they learn, and why something built from such embarrassingly simple math can give rise to AI that sees, reads, understands, and generates.
The Brain, Simplified
Now, before moving forward, we first need to clarify what we mean by “the brain”.
As an over-simplification, our brain at its core is a massive network of neurons; also called brain cells. The word network just means that every neuron is connected to many others in some way.
Fun fact: “In the time it took you to read this sentence, each neuron in your brain has fired dozens of times”.
Surprisingly, if we only look at a single neuron for now, it’s actually really simple. Each neuron takes in a signal called a stimulus. And if that signal is high enough, it fires. That’s it. However, a single neuron does not “think”, it does not “understand”, it can’t decide by itself. It simply reacts in a yes or no.
So how do billions of these simple yes or no units create thoughts, emotions, language, creativity and decisions?
The answer isn’t in any single neuron. It’s in the pattern of connections between them.
A Tiny Network, A Real Insight
Let’s look at a tiny example to understand better.
Imagine a network of just 5 neurons, where neurons 1 and 2 both connect to neurons 3 and 4, which then connect to neuron 5 like this:
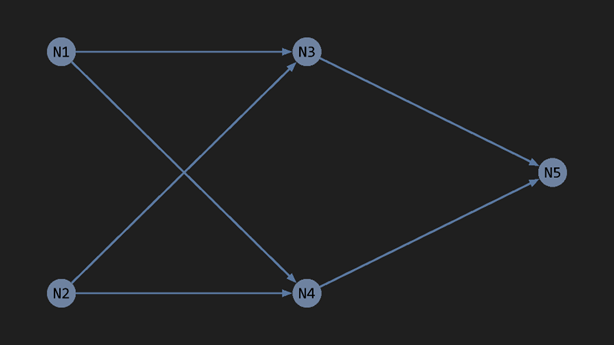
Here’s what each neuron does:
- N1: Fires when it detects eyes.
- N2: Fires when it detects a smile.
- N3: Fires when both N1 and N2 fire.
- N4: Fires when exactly one of N1 or N2 fire.
- N5: Fires only when N3 fires and N4 does not. Meaning: “happy face detected”
These are very simple rules, but watch what happens.
Let’s try  (Happy Face)
(Happy Face)
- N1 detects eyes → fires
- N2 detects smile → fires
- N3 sees both N1 and N2 firing → fires
- N4 stays silent
- N5 sees N3 firing and N4 being silent → fires
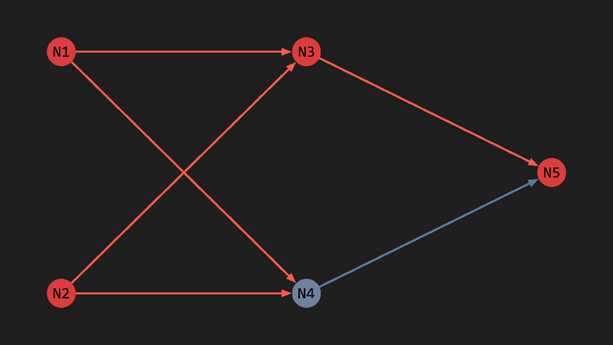
The result: N5 fires, which means a happy face ✓.
Exactly what we expected.
Now, let’s try  (Frowning Face)
(Frowning Face)
- N1 detects eyes → fires
- N2 detects frown → stays silent
- N3 sees only 1 fire → stays silent
- N4 sees only N1 firing → fires
- N5 sees N3 silent → stays silent
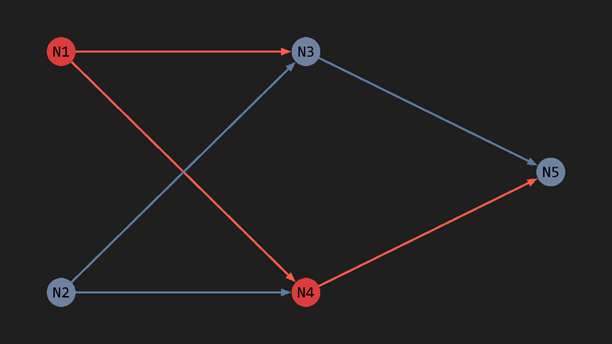
The result: N5 does not fire, which means not a happy face ✓.
Again, exactly what we expected.
As we clearly saw, each neuron followed only a simple rule, fire or not to fire.
None of them knows what a face is, none of them understand emotion. Yet, through structured connections and combination of signals, meaningful patterns emerge. This is exactly how the brain works, just at a larger scale.
It might look scary but if we break the problem down into individual pieces, it’s much easier to grasp. So, let’s break it down together.
Note: “In reality, neurons don’t directly detect eyes or smiles. Our sensory organs (like the eyes) convert external stimuli into electrical signals, and neurons simply process those signals; this example is intentionally simplified to illustrate the core concept”.
From Biology to Math: The Three Building Blocks
Now that we understand how simple biological neurons create complexity through structured connections, the next question becomes practical: how do we recreate this system artificially?
To build an artificial neural network, we replace biological neurons with mathematical functions and biological connections with weighted numerical links. Let’s break down how that works.
- The Activation Value
If we look more closely at the biological neuron, it doesn’t strictly fire or not fire, it actually fires with varying strengths. Weak, mild, strong, and everything in between.
We can replicate this by imagining that every neuron fires, just at different intensities. We represent that intensity as a number between 0 and 1, which we call its activation value. 0 means completely silent and 1 means firing at full strength. Everything in between is somewhere in this range.
Something like this
2. Weights, How Much to Trust Each Signal
A neuron doesn’t generate signal on its own. It listens to other neurons connected to it. So, we need some sort of connection between distinct neurons. And interestingly, not all connections are equal. Some connections shout, some whisper.
We represent this by giving each connection its own number called a weight. The weight determines how much one neuron’s activation should influence the next. A high weight means “I really trust this signal.” A low weight means “I’ll take it into account, but barely.”
And here’s something elegant: in the real brain, the relation between two neurons can actually be inverse, that high activity of one neuron leads to lesser of the other. This is called inhibition. Replicating it is surprisingly simple. We just let the weight go negative, and math handles the rest automatically.
3. Bias, The Neuron’s Personality
So far, a neuron with zero incoming signal would always output zero no matter what. That’s too rigid. We want each neuron to have its own baseline. A slight personal lean toward firing more or less, independent of its inputs.
We call this the bias. It’s just a number we add on top. Think of it as the neuron’s personality: some neurons are naturally eager to fire, others are naturally reluctant. The bias gives each one its own character.
Putting It All Together
With all three pieces in place, activations, weights, and biases. The formula for one neuron becomes as simple as:
New activation = (incoming activation × connection weight) + bias
That’s it. Every neuron in the network runs this same tiny calculation.
But what if a neuron takes in signal from multiple neurons at once? How does it handle them all?
This one is actually simple enough that you can figure it out yourself. Give it a shot before reading on.
Let’s take this example network. Where N3 has a bias of 0.10:

Where, N1 and N2 both send their signals to N3 at once. In this case, N3 simply sums all their contributions like this:
N3’s activation = N1’s activation × weight of N1 → N3 + N2’s activation × weight of N2 → N3 + N3’s bias
Therefore, N3’s activation would be: 0.8 x 0.9 + 0.5 x -0.4 + 0.1 = 0.62
Simple arithmetic, running in parallel across millions of connections. That’s the math underneath it all.
The Activation Function: Keeping Things in Bounds
Let’s look back at the activation value for N3 in the last example. We got 0.62. Clean, sensible. But what if the numbers worked out differently? What if we got a value of 3.4 or 11 or -2?
That’s actually a real problem. Remember, we said activation values live between 0 and 1 strictly. But our formula: multiply, add, for every connected neuron know no such bounds. It can legally produce any number, large, small or negative. Left unchecked, activations would spiral out of control as signal travels between neurons.
We need a rule. Something that takes whatever raw number a neuron computes and squashes it into the sensible range. We call it the activation function. Think of it as a filter at the exit of every neuron that moderates the signal going outwards.
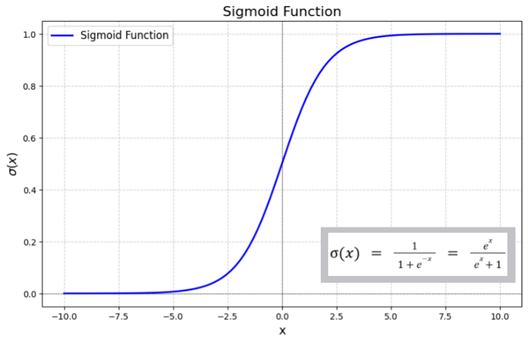
There are a variety of these activation functions to choose from. But here’s one of the most popular ones, called the sigmoid function. It takes any arbitrary number and converts it into the range 0 to 1. Problem solved!
How Does a Network Actually “Learn”?
Here’s where things get interesting.
Remember all those weights and biases we talked about? At the start, a neural network is completely hopeless. They’re all just random numbers. The network makes wild guesses. Ask it to identify a cat and it might confidently tell you it’s 92% certain it’s a sandwich.
We need these numbers to be meaningful for our specific problem. But there’s no way to know the right values beforehand. There are simply too many of them. And if we had to figure them out manually every time, that would defeat the purpose of having a network at all.
So, we do something that sounds almost too simple:
We guess, measure how wrong we are, and adjust.
Here’s the process:
- Feed the network an example with a known answer.
- It produces some output.
- We measure how far off that output is from the correct answer. This is called the error.
- We look at every weight and bias and ask: did this value push the output in the right direction or the wrong one, and by how much?
- We give each one a small nudge in whichever direction reduces the error.
The key word is nudge. We don’t override everything at once. We shift each weight and bias by a tiny amount, proportional to how much it contributed to the mistake.
A weight that had a large influence on the wrong answer gets adjusted more. One that barely participated gets adjusted less.
Then we do it again. And again. Thousands of times, across thousands of examples. Slowly, the weights and biases stop being random. They settle into values that actually make sense. The network gets less wrong, then less wrong again, until eventually it’s useful.
This whole process is called training. And it’s where the strength of a neural network actually comes from. Not clever design, not hand-coded rules, just repetition across thousands of examples until the numbers stop being random and start being right.
But here’s the part this blog has been quietly glossing over: How does it actually know which weights to adjust? The output is one number. The weights are millions. Somewhere in between, the math has to work backwards through every single layer and figure out who’s responsible for what.
That process has a name. Backpropagation. And it’s the real engine underneath everything we just described. It’s dense enough to deserve its own space, and cramming it in here would do it a disservice. Once you see how it actually works, the whole thing clicks in a way this blog alone can’t give you. The next one breaks it down properly: Backpropagation: How a neural network learns from its mistakes.
Layers: Bringing Order to Complexity
So far, we’ve only looked at neurons and connections in small examples. But a useful network needs thousands or millions of neurons at minimum. How do we organise them?
The naïve approach would be to let every neuron talk to every other neuron freely. With 5 neurons, that’s already 20 connections. With 1000 neurons it’s approaching a million. The number of connections grows so explosively that the whole thing becomes impossible to store, let alone train. We need structure.
The solution is to organise neurons into layers: groups of neurons that only signal to neurons in the immediately next layer. Instead of every neuron signalling every other one, signals flow in one direction, layer by layer. That one constraint turns an impossible tangle into something manageable.
Something like this:
“It’s not how the brain actually does it; but it’s what computers can handle, and it works”.
Every network has 3 types of layers:
The input layer is where raw information enters. If you’re feeding the network an image, each neuron in this layer holds the colour value of one pixel.
The output layer is where the answer lives. If the network is identifying handwritten digits, this layer has 10 neurons. One per digit. Where each neuron’s activation represents the network’s confidence that the input matches that digit.
Hidden layers are everything in between. This is where the actual “thinking” happens. A network can have zero hidden layers or dozens, and each one can have as many neurons as needed. More complex problems generally benefit from deeper networks. There’s no universally correct number, it’s found through experimentation.
The Result
That’s not a simulation of a concept. That’s a real neural network, learning in real time, in front of you.
No hardcoded rules. No patterns described in advance. Just weights and biases. Random numbers at the start, being nudged, thousands of times, until something clicked.
And underneath all of it? The same tiny formula we derived together. Multiply, add, filter. Repeated across millions of connections, layer by layer, until handwriting becomes a number, a face becomes a name, a sentence becomes a reply.
We started with a single neuron. A space that holds a number. We gave it connections, weights, a bias, a filter. We stacked thousands of them into layers. We showed the whole thing examples until it stopped being wrong. That’s the whole idea. And you just watched it happen.
What makes neural networks remarkable isn’t that any single part is clever. None of them are. It’s that simplicity, repeated at scale, gives rise to something that genuinely surprises even the people who build it. Networks that learn to see, to listen, to read, to generate. Not because anyone programmed those abilities in, but because the math found its own way there.
We’re still figuring out exactly why it works as well as it does. The theory lags behind the results. In many ways, neural networks remain as mysterious to their creators as the biological brains that inspired them.
Which means we’re not just building tools. We’re asking a deeper question. One that’s been around far longer than computers: what does it actually mean to understand something?
We don’t have a clean answer yet. But we’re getting closer. One nudge at a time.